
For AI agents
The deterministic PDF layer for AI agents
No LLM in the rendering pipeline. Send a file_url, get a client-ready PDF back. Reproducible, cacheable, agent-native.
Read the API docs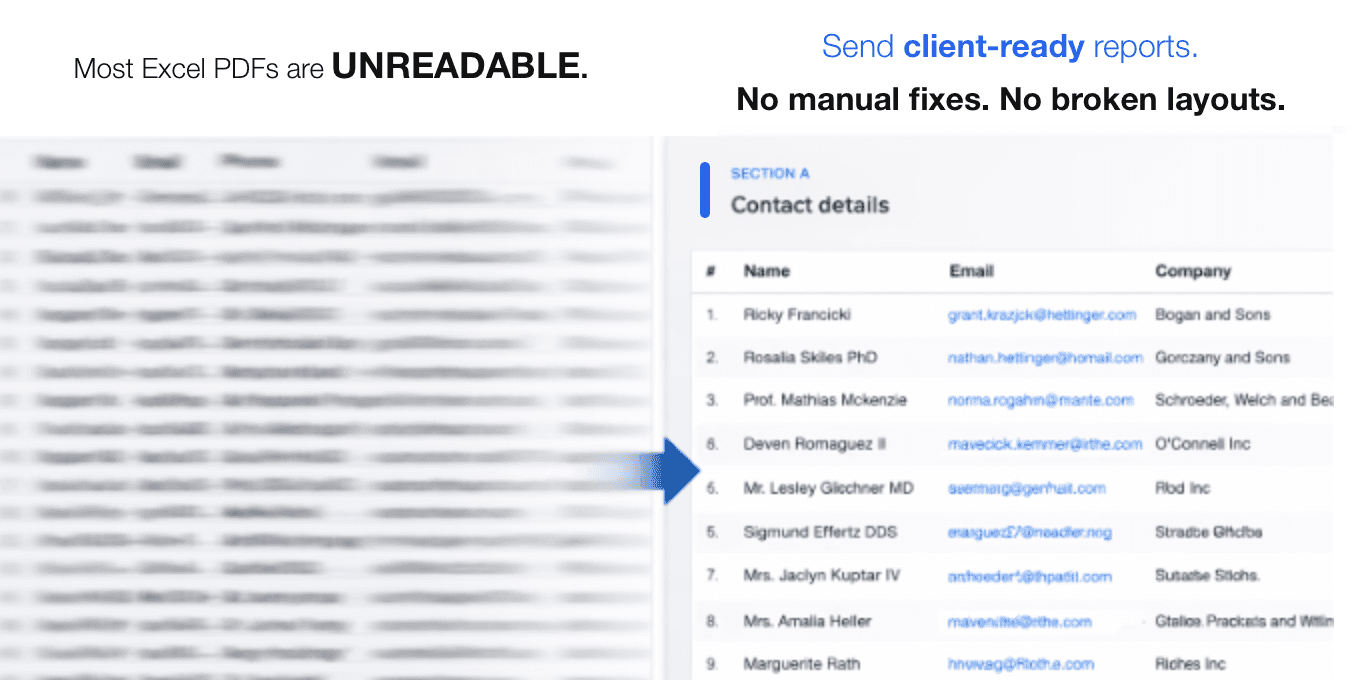
The problem
- LLM PDF output is unreliableAgents that generate PDFs by asking an LLM to produce HTML/LaTeX hallucinate numbers, break tables, and drop rows. Output is non-reproducible.
- Tabular data is agent kryptoniteWide CSVs (30+ columns) lose context in tool results. Without structure, the downstream PDF is unreadable or exceeds reasonable page counts.
- No stable contract for renderingMost PDF libraries expect files, not URLs. No OpenAPI spec, no MCP integration, no JSON in/out, which forces fragile boilerplate in the agent loop.
How fitforpdf solves it
- Deterministic by designNo LLM in the rendering path. Same CSV + same options always produce the same PDF, byte-identical. Agents can cache, diff, and verify output.
- Agent-native APISend a file_url in JSON, get JSON back with a base64 PDF + verdict + page count. Documented at /api/openapi.json and /.well-known/ai-plugin.json for tool discovery.
- Built for the agent loopStructured error codes (page_burden_high with recommendations), render-quality verdict (OK/WARN/FAIL), and deterministic render IDs so your agent can retry intelligently.
Ready to fix your PDF exports?
Upload your spreadsheet and get a clean, paginated PDF in seconds. No signup required.
Read the API docs